How BAM Works: A Security-First Technical Deep Dive into Jito's Block Assembly Marketplace
Introduction
Jito, one of the pioneers of MEV infrastructure on Solana, recently released BAM (Block Assembly Marketplace)—a validator client architecture designed to enhance pre-execution transaction privacy, provide auditable and deterministic execution, and unlock capabilities such as ACE (Application Controlled Execution).
BAM represents a fundamental shift in how Solana validators handle transaction ordering and execution. Unlike the previous Jito-Solana architecture where bundles were processed through dedicated on-chain stages, BAM introduces a Trusted Execution Environment (TEE) layer that sequences transactions off-chain before they reach the validator. This architectural change addresses key concerns in Solana's single-leader model while maintaining the network's high-performance characteristics.
This blog provides a security-first approach to analyzing the BAM client codebase. When Jito announced their $100,000 Immunefi bounty, it presented the perfect opportunity—not just to hunt for bugs, but to dive deep into how this next-generation MEV infrastructure actually works at the code level.
BAM extends from jito-solana in the following ways:
- TEE-based transaction sequencing for pre-execution privacy
- Dynamic runtime switching between BAM and traditional processing
- Unified bundle and transaction execution in the banking stage
- Atomic transaction batches with strict FIFO ordering
This technical breakdown aims to provide a comprehensive reference for anyone looking to understand how BAM works under the hood.
What Is BAM?
BAM (Block Assembly Marketplace) is a modified Solana validator client that shifts transaction sequencing from the validator to an off-chain TEE environment. Unlike the previous Jito architecture where bundles had a separate execution path, BAM processes both regular transactions and bundles through a unified banking stage pipeline.
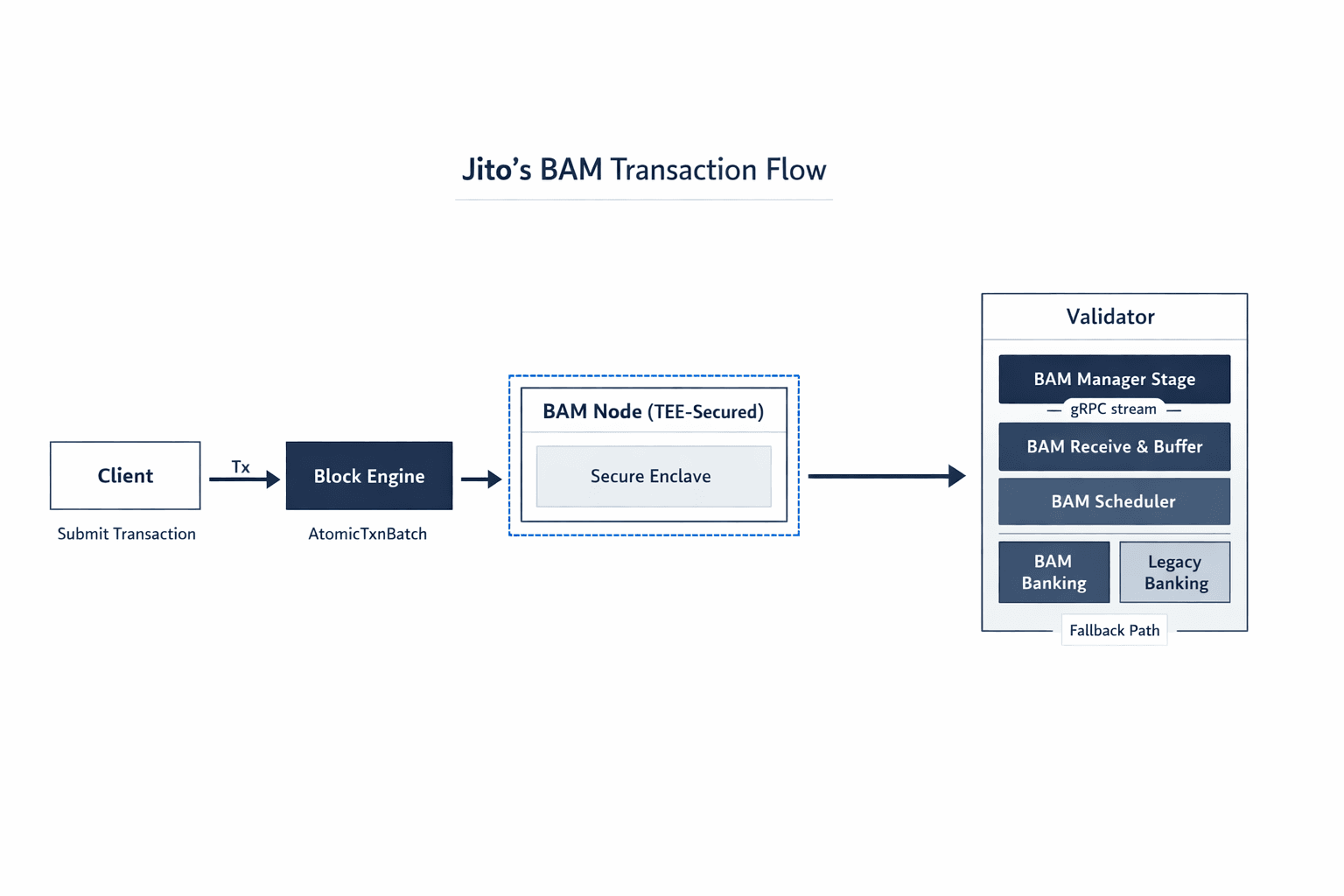
Core Components
- BAM Node (Off-chain): TEE-secured sequencing engine that orders transactions before execution
- BAM Manager Stage: New component that establishes and maintains gRPC connection to BAM node
- BAM Receive & Buffer: Validates and buffers atomic transaction batches from BAM
- BAM Scheduler: Schedules batches using priority-based ordering derived from sequence IDs
- Modified Banking Stage: Dual-pipeline architecture supporting both BAM and traditional processing
The BAM Value Prop
Deterministic Execution: Strict FIFO ordering enforced by the BAM node provides auditable, verifiable transaction ordering
Application Controlled Execution (ACE): Plugins on the BAM node can inject custom logic (e.g., oracle updates) before sequencing
For conceptual overviews of BAM, refer to:
For a technical deep dive into how jito-solana works, refer to:
Technical Architecture Breakdown
Runtime State Management
One of BAM's most critical features is its dynamic runtime switching capability. Validators can enable or disable BAM without restarting, controlled through the Admin RPC API.
This is implemented via a shared atomic boolean:
// core/src/tpu.rs
let bam_enabled = Arc::new(AtomicBool::new(false));State Transitions:
- Set to
trueonly when:- BAM connection is healthy (receiving heartbeats)
- Bam-related config is received from BAM node and validated
- When
false: All transactions fall back to traditional Jito-Solana pipeline
Why This Matters:
This design allows validators to seamlessly fall back to proven Jito-Solana processing if BAM encounters issues, ensuring continuous block production. It's a safety mechanism that reduces operational risk for validators adopting BAM.
BAM Manager Stage
The BAM Manager Stage is the connection layer between the validator and the BAM node. It establishes a persistent bidirectional gRPC stream that handles authentication, configuration updates, and message routing.
Key Responsibilities
- Connection Management: Establish and maintain gRPC connection to BAM node
- Authentication: Challenge-response protocol to verify validator identity
- TPU Advertisement: Redirect client transactions to BAM node via gossip
- Message Routing: Forward transaction batches inbound, execution results outbound
- Health Monitoring: Track heartbeats and mark connection as unhealthy if stale
Authentication Flow
BAM uses Ed25519 challenge-response authentication to prevent unauthorized transaction injection:
// core/src/bam_manager_stage.rs
// Signature domain separation prevents cross-context attacks
const AUTH_LABEL: &[u8] = b"bam-auth-challenge";
// Sign challenge with validator keypair
let signature = keypair.sign_message(
&[AUTH_LABEL, challenge.as_bytes()].concat()
);Security Properties:
- Domain Separation: The
AUTH_LABELprefix prevents signature reuse in other contexts - Validator Identity: Only the validator with the correct keypair can authenticate
- Challenge Freshness: New challenges for each connection attempt
TPU Advertisement
Once authenticated, the validator redirects all client traffic to the BAM node by updating its gossip-advertised TPU addresses:
// core/src/bam_manager_stage.rs
// Update gossip to redirect clients to BAM node
cluster_info.push_tpu_addresses(bam_tpu_addresses);Impact:
- Clients sending transactions to the validator's advertised TPU will actually send to BAM
- BAM becomes the first point of contact for all transactions
- The validator only receives pre-sequenced transaction batches from BAM
Message Protocol
BAM uses a Protobuf-based bidirectional protocol:
Outbound Messages (Validator → BAM):
| Message Type | Purpose | Frequency |
|---|---|---|
AuthProof | Initial authentication | Once per connection |
ValidatorHeartbeat | Liveness proof | Every 5 seconds |
LeaderState | Slot/tick/CU budget updates | During leader slots |
MultipleAtomicTxnBatchResult | Execution results | After batch processing |
Inbound Messages (BAM → Validator):
| Message Type | Purpose | Frequency |
|---|---|---|
AuthProof | Initial authentication | Once per connection |
ValidatorHeartbeat | Liveness proof | Every 5 seconds |
Latency Considerations
BAM introduces an additional network hop with regards to bundle submission. The following diagram shows the comparison between Jito-Solana and BAM architectures:
Mitigation Strategies:
- gRPC streaming reduces per-message overhead
- BAM node co-location with validators minimizes network distance
Integration with Other Components
- Downstream: Forwards
AtomicTxnBatchmessages to BAM Receive & Buffer via crossbeam channel - Upstream: Receives execution results from BAM Scheduler and streams back to BAM node
- Health Monitoring: Sets
bam_enabledflag based on connection health and configuration
BAM Receive and Buffer
The BAM Receive and Buffer component is the gatekeeper between the BAM Manager and the transaction scheduler. It performs critical validation on transaction batches to ensure they're safe for execution.
Key Responsibilities
- Deserialization: Convert Protobuf
AtomicTxnBatchto native Solana packets - Signature Verification: Cryptographically verify all Ed25519 signatures
- Transaction Parsing: Deep validation against SVM execution rules
- Container Insertion: Buffer validated transactions for scheduler consumption
- Error Reporting: Send detailed failure reasons back to BAM node
Processing Pipeline
When BamReceiveAndBuffer::new() is initialized, it spawns a dedicated parsing thread that processes batches asynchronously:
// core/src/banking_stage/transaction_scheduler/bam_receive_and_buffer.rs
// Spawn dedicated thread for batch validation
let parsing_thread = Builder::new()
.name("bam_parse".to_string())
.spawn(move || {
Self::parsing_loop(/* ... */)
})?;Thread Architecture:
- Main thread: Receives from
bundle_receiver, forwards to parsing thread - Parsing thread: Runs all validation, sends results to scheduler
- Response thread: Reports errors/success back to BAM Manager
Validation Pipeline
Step 1: Batch Reception
The parsing loop uses burst reception to handle high transaction volumes:
// core/src/banking_stage/transaction_scheduler/bam_receive_and_buffer.rs
// Hybrid strategy:
// - Block for up to 1ms for first batch
// - Then non-blocking drain up to 128 batches
fn batch_receive_until(
bundle_receiver: &crossbeam_channel::Receiver<AtomicTxnBatch>,
recv_buffer: &mut Vec<AtomicTxnBatch>,
start: &Instant,
recv_timeout: Duration, // 1ms
batch_count_upperbound: usize, // ATOMIC_TXN_BATCH_BURST (128)
) -> Result<(usize, usize), RecvTimeoutError> {
// Blocking receive with timeout: wait at most 1ms for first batch
let batch = bundle_receiver.recv_timeout(recv_timeout)?;
let mut num_packets_received = batch.packets.len();
let mut num_atomic_txn_batches_received = 1;
recv_buffer.push(batch);
// (Non-blocking) Continue trying to receive more packets
while let Ok(batch) = bundle_receiver.try_recv() {
trace!("got more packet batches in bam receive and buffer");
num_packets_received += batch.packets.len();
num_atomic_txn_batches_received += 1;
recv_buffer.push(batch);
if start.elapsed() > recv_timeout || recv_buffer.len() >= batch_count_upperbound {
break;
}
}
Ok((num_packets_received, num_atomic_txn_batches_received))
}
Why This Works:
- Amortizes processing overhead across multiple batches
- Prevents thread thrashing from constant context switching
- Balances latency (1ms wait) with throughput (128 batch burst)
Step 2: Pre-validation Checks
Before expensive cryptographic verification, basic invariants are checked:
Pre-validation checks in bam_receive_and_buffer.rs
- The batch has not expired yet (
max_schedule_slot>=current_slot) - The batch is not empty
- The batch does not have more than 5 packets
- All transactions have consistent revert_on_error flags
Rationale:
- Early rejection saves CPU on invalid batches
revert_on_errorconsistency ensures atomic rollback behavior- Size limit prevents resource exhaustion
Step 3: Signature Verification
Once the batches have been pre-validated, signature verification is performed.
ed25519_verify(&mut packet_batches, false, packet_count);Security Note: While BAM already verified signatures, the validator re-verifies to eliminate trust in the BAM node for cryptographic correctness.
Step 4: Deep Transaction Parsing
The next steps involve validation checks specific to SVM execution and consensus rules. Many of these checks are extracted from the banking stage. Running these checks earlier enables invalid transactions to be filtered out earlier. The most complex validation phase performs 8 critical checks; these checks are run for every packet in a verified batch:
1. Vote Transaction Filter
if view.is_simple_vote_transaction() {
return Err(Reason::DeserializationError);
}BAM does not currently support processing vote transactions
2. Address Lookup Table (ALT) Resolution
let load_addresses_result = match view.version() {
TransactionVersion::Legacy => Ok((None, u64::MAX)),
TransactionVersion::V0 => root_bank
.load_addresses_from_ref(view.address_table_lookup_iter())
.map(|(loaded_addresses, deactivation_slot)| {
(Some(loaded_addresses), deactivation_slot)
}),
};
let Ok((loaded_addresses, deactivation_slot)) = load_addresses_result else {
return Err(Reason::DeserializationError());
};
let Ok(view) = RuntimeTransaction::<ResolvedTransactionView<_>>::try_new(
view,
loaded_addresses,
root_bank.get_reserved_account_keys(),
) else {
return Err(Reason::DeserializationError());
};
For version 0 transactions, addresses are loaded from the bank's lookup table. If resolution fails (e.g., missing keys or deactivation), the transaction is rejected.
3. Account Lock Validation
if let Err(err) =
validate_account_locks(view.account_keys(), transaction_account_lock_limit)
{
return Err(Reason::TransactionError);
}If there are duplicate accounts detected or Total number of account locks > 128 (limit), the transaction is rejected
4. Compute Budget Instruction Validation
let (result, duration_us) = measure_us!(view
.compute_budget_instruction_details()
.sanitize_and_convert_to_compute_budget_limits(&working_bank.feature_set));
let fee_budget_limits = match result {
Ok(fee_budget_limits) => fee_budget_limits,
Err(err) => {
return Err(Reason::TransactionError);
}
};Sanitizes compute budget instructions, ensuring there is no conflicting instructions and that the compute unit limit ≤ maximum allowed (1.4M CUs).
5. Blockhash Validity
let lock_results: [_; 1] = core::array::from_fn(|_| Ok(()));
let (check_results, duration_us) = measure_us!(working_bank.check_transactions(
std::slice::from_ref(&view),
&lock_results,
MAX_PROCESSING_AGE,
&mut TransactionErrorMetrics::default(),
));
if let Some(Err(err)) = check_results.first() {
return Err(Reason::TransactionError);
}Verifies that the blockhash is recent (in the current working bank's queue), not older than MAX_PROCESSING_AGE (150 slots), and not duplicated (prevents signature dedup).
6. Fee Payer Balance Check
let fee_payer = transaction.message().fee_payer();
let required_fee = bank.get_fee_for_message(transaction.message())?;
let balance = bank.get_account(fee_payer)?.lamports();
if balance < required_fee {
return Err(ParseError::InsufficientFunds);
}Confirms the fee payer has sufficient lamports for the transaction fee
7. Blacklist Filter
let touches_blacklist = transaction.message()
.account_keys()
.iter()
.any(|key| blacklisted_accounts.contains(key));
if touches_blacklist {
return Err(ParseError::BlacklistedAccount);
}Ensure none of the transactions touch the blacklisted tip payment program, preventing stealing tips mid-slot
8. Cost & Priority Calculation
let cost = CostModel::calculate_cost(transaction, &bank);
let priority = seq_id; // Lower seq_id = higher priority (FIFO)
let batch_metadata = BatchMetadata {
cost,
priority,
max_age: current_slot + MAX_PROCESSING_AGE,
revert_on_error,
};Computes transaction cost using Solana's QoS model, factoring in the requested compute units, loaded accounts data size, write lock costs and signature verification costs.
Priority is derived from the batch's seq_id (lower ID = higher priority). This FIFO-aligned priority feeds into the transaction scheduler, with cost used for resource allocation.
Successfully validated batches are inserted into the Transaction State Container
Transaction Scheduling
Once batches are validated and inserted into the transaction state container, they enter admission control—a leadership-aware process that determines whether batches should be buffered, rejected, or discarded.
Leadership-Aware Admission
The admission decision is driven by the validator's proximity to becoming the leader:
| Decision | Validator State | Batch Handling |
|---|---|---|
Consume | Currently producing blocks | Buffer for execution |
Hold | About to become leader (warmup) | Buffer for upcoming execution |
Forward | Far from leader slot | Reject all batches |
ForwardAndHold | Transitioning states | Reject all batches |
BAM does not forward sequenced batches to other validators. Since the BAM node finalizes ordering within its TEE-secured enclave, forwarding would violate the verifiable sequencing guarantees. Instead, non-leader validators explicitly reject batches with OutsideLeaderSlot errors.
Admission Control Flow
Admission control logic in bam_receive_and_buffer.rs
The core flow involves receiving parsed batches from a channel and making decisions based on leadership status.
-
In
ConsumeorHoldmode: Batches are drained from the receiver and inserted into the container if BAM is enabled. If the container is full, batches are rejected with feedback to the BAM node, preventing silent drops that could disrupt ordering attestations. -
In
ForwardorForwardAndHoldmode: The container is pruned by popping and removing batches, followed by rejecting incoming ones within a timed deadline (e.g., 100ms) to avoid indefinite blocking.
This integrates with the scheduler by preparing prioritized batches.
- Priority is derived from
seq_id(assigned in FIFO order by BAM nodes), where lower values indicate higher priority, enforcing the TEE-defined sequence.
Explicit Rejection Mechanism: Rejections send structured responses via a sender channel, using protobuf messages for interoperability with BAM nodes.
- This provides detailed feedback (e.g., error codes for batch rejection)
Integration with Scheduler Controller
Scheduler controller integration
The Scheduler Controller acts as an orchestrator, transitioning batches from admission to execution. It calculates available compute budgets using a CostPacer (if present), which paces execution to avoid overwhelming the slot's capacity. Scheduling then occurs only in Consume mode, applying pre-graph filters to validate against the current bank state.
Key constraints include:
- Ordering Guarantees: Batches are scheduled strictly by
seq_idpriority, preserving BAM's verifiable sequence. - Cost Pacing: Gradual release of execution capacity prevents bursty overloads, using Instant for time-based budgeting—a Rust standard for monotonic clocks, avoiding pitfalls like system time adjustments.
- Final Validation: A pre-scheduling check re-validates transactions, addressing time-based drifts (e.g., expired blockhashes).
Pre-Scheduling Validation
Even though batches were already validated during receive-and-buffer, a final check is performed before scheduling:
Pre-scheduling validation in scheduler_controller.rs
This involves verifying blockhash age, duplicate processing, account existence, and balance sufficiency using the bank's check_transactions() method.
Why is the revalidation needed?
- Time has elapsed since initial validation
- Bank state has changed (other transactions executed)
- Blockhashes may have expired
- Duplicate transactions may have been processed
BAM Scheduler
The BAM Scheduler is a specialised transaction scheduler that handles atomic batch execution. Unlike the traditional PrioGraphScheduler which optimizes for maximum throughput across independent transactions, the BAM Scheduler enforces strict atomic semantics—if any transaction in a batch fails, the entire batch is rolled back.
Key Differences from PrioGraphScheduler
| Aspect | PrioGraphScheduler | BAM Scheduler |
|---|---|---|
Atomicity | Per-transaction | Per-batch (all-or-nothing) |
Ordering | Account-dependency graph | Strict FIFO by `seq_id` |
Rollback | Individual failures | Batch-wide rollback |
State Tracking | Transaction IDs only | Full batch metadata |
Use Case | Independent transactions | MEV bundles, atomic batches |
Architecture
pub struct BamScheduler<Tx: TransactionWithMeta> {
// Worker pool communication
consume_work_sender: Sender<ConsumeWork<Tx>>,
finished_consume_work_receiver: Receiver<FinishedConsumeWork<Tx>>,
// Result reporting
response_sender: Sender<BamOutboundMessage>,
// Batch tracking for atomicity
next_batch_id: u64,
inflight_batch_info: HashMap<TransactionBatchId, InflightBatchInfo>,
prio_graph: SchedulerPrioGraph,
insertion_to_prio_graph_time: HashMap<u32, Instant>,
time_in_priograph_us: Histogram,
time_in_worker_us: Histogram,
time_between_schedule_us: Histogram,
last_schedule_time: Instant,
slot: Option<Slot>,
// Reusable objects to avoid allocations
reusable_consume_work: Vec<ConsumeWork<Tx>>,
reusable_priority_ids: Vec<Vec<TransactionPriorityId>>,
extra_checks_enabled: bool,
bank_forks: Arc<RwLock<BankForks>>,
}
// A structure to hold information about inflight batches.
// A batch can either be one 'revert_on_error' batch or multiple
// 'non-revert_on_error' batches that are scheduled together.
struct InflightBatchInfo {
pub schedule_time: Instant,
pub batch_priority_ids: Vec<TransactionPriorityId>,
pub slot: Slot,
}
Scheduling Flow
Phase 1: Batch Selection
Batch selection in bam_scheduler.rs
The scheduler pulls batches from the container in priority order (determined by seq_id), skipping if the slot has advanced beyond the batch's max schedule slot.
- If extra checks are enabled, transactions are re-verified against the working bank, rejecting batches with errors.
- Valid batches are inserted into the priority graph with account access metadata.
Phase 2: Worker Dispatch
Worker dispatch in bam_scheduler.rs
Batches receive unique IDs (incrementing u64), with metadata stored in the inflight map. Work items are created and sent round-robin to workers, promoting load balancing.
Worker Pool Strategy:
- 8 dedicated BAM worker threads (vs. configurable for regular pipeline)
- Round-robin distribution for load balancing
- Each worker can handle any batch (no specialization)
Phase 3: Result Collection
Result collection in bam_scheduler.rs
Workers report execution results back to the scheduler.
- Completed work is received non-blockingly, retrieving metadata to build results.
- If any transaction fails, the batch is marked
NotCommittedwith the error; otherwise, it's Committed with per-transaction details (e.g., compute units, slot).
Integration with Workers
BAM workers are created with tip processing capabilities:
// core/src/banking_stage/consumer.rs
let workers: Vec<_> = (0..num_workers)
.map(|id| {
ConsumeWorker::new_with_tip_processing_deps(
id,
exit.clone(),
consume_receiver.clone(),
consumer.clone(),
consumed_sender.clone(),
shared_leader_state.clone(),
tip_processing_dependencies.clone(),
)
})
.collect();Worker Responsibilities:
- Receive
ConsumeWorkfrom scheduler - Execute transactions against bank in sequence
- On failure: Roll back bank state, return error
- On success: Commit to PoH, process tip payments, return results
Banking Stage: Dual-Pipeline Architecture
The Banking Stage serves as the top-level orchestrator for Solana's transaction processing. When BAM is enabled, it manages a dual-pipeline architecture that runs both the regular transaction scheduler and the dedicated BAM scheduler in parallel.
Why Dual Pipelines?
This architecture enables:
- Seamless Fallback: Switch between BAM and traditional processing without restart
- Operational Safety: Continue block production if BAM connection fails
Initialization: Spawning Parallel Pipelines
BAM spawns 8 workers with shared channels for work-stealing, supporting tip processing. A dedicated scheduler thread initializes components like BamReceiveAndBuffer and SchedulerController, running an event loop for admission, scheduling, and results.
Thread Responsibilities:
- BamScheduler: Coordinates batch scheduling and atomicity tracking
- BamReceiveAndBuffer: Validates incoming batches, buffers for scheduler
- SchedulerController: Orchestrates admission, scheduling, and result collection
Mutual Exclusion via bam_controller Flag
The SchedulerController respects the bam_controller flag to implement mutual exclusion:
Mutual Exclusion Property:
- When
bam_enabled=true: Only BAM controller schedules - When
bam_enabled=false: Only regular controller schedules - Never both active simultaneously
Tip Processing in BAM
BAM maintains tip payment compatibility with the Jito ecosystem through the Tip Payment and Tip Distribution programs. However, unlike the previous Jito-solana architecture where tips within bundles were handled in a dedicated BundleStage, BAM processes tips during the banking stage.
Tip Processing Flow
1. Blacklist Filtering During Receive and Buffer
As mentioned earlier, transactions that include the tip payment programs in their accounts array are filtered out in BamReceiveAndBuffer.
2. Spawning workers capable of handling tips in the Banking Stage
pub fn new_with_tip_processing_deps(
id: u32,
exit: Arc<AtomicBool>,
consume_receiver: Receiver<ConsumeWork<Tx>>,
consumer: Consumer,
consumed_sender: Sender<FinishedConsumeWork<Tx>>,
shared_leader_state: SharedLeaderState,
tip_processing_dependencies: Option<TipProcessingDependencies>,
) -> Self {
Self {
exit,
consume_receiver,
consumer,
consumed_sender,
shared_leader_state,
metrics: Arc::new(ConsumeWorkerMetrics::new(id)),
tip_processing_dependencies,
}
}
The TipProcessingDependencies struct contains critical fields required for tip processing:
tip_manager: Handles tip program interactions, including bundle creation for initialization and cranking.last_tip_updated_slot: Tracks the most recent slot where tips were processed, ensuring once-per-slot semanticsblock_builder_fee_info: Contains the block builder's Pubkey and commission rate, retrieved from BAM node configurationbundle_account_locker: Manages account locking for bundle execution, ensuring atomicity.
3. Worker Tip Processing in the Consume Loop
Within each worker's consume function—called via the main run loop and consume_loop—tip programs are executed conditionally before processing the batch.
// Update tip account receivers if needed
if !self.run_tip_programs_if_needed(bank, &work.transactions) {
error!(
"Error running tip programs for transactions: {:?}",
work.transactions
);
datapoint_error!(
"consume-worker-error",
("error", "tip_programs_error", String),
);
}The run_tip_programs_if_needed() function, invoked at the start of every slot for relevant batches, performs slot-level tip setup and distribution. This includes:
- Slot-Level Check: A locked guard on
last_tip_updated_slotverifies if tips were already processed for the current bank slot. If so, it skips to avoid redundant computations. - Tip Distribution Cranking: A "crank" bundle with two transactions are created: the first one involves
initializingthe tip distribution account and the second one involves updating the tip receiver.
Following tip processing, the worker proceeds to execute the batch transactions against the current bank, committing results and handling atomic rollbacks as needed.
Conclusion
BAM represents a significant evolution in Solana's MEV infrastructure. By moving transaction sequencing into a TEE-secured environment and unifying bundle and transaction processing, BAM addresses key concerns around pre-execution privacy, deterministic execution, and application-controlled ordering.
Through this deep dive into the Jito BAM client codebase, we’ve unpacked the mechanics behind BAM’s integration into Solana’s transaction pipeline, grounding its design goals in concrete implementation details. As Solana continues to modularize its execution and scheduling stack, understanding these internal boundaries becomes increasingly important.
I'm currently interested in exploring Solana security and building on the SVM, feel free to reach out to me at @Ril1111 on X. Always keen to collaborate on uncovering deeper execution-layer insights or auditing consensus and client-side infrastructure.